Effective Comments and Javadoc
This lesson provides an overview of effective commenting strategies, including Javadoc style commenting for automated documentation
We have previously looked at how we can add comments to our code using // and /* */.
class Character {
public:
// This is a single-line comment
int GetHealth() { return mHealth; }
private:
/* This comment can span
* multiple lines
*/
int mHealth;
};Whilst knowing how to comment is useful, there is a more nuanced topic, around knowing when to comment.
Commenting for Future Work
Often when we're writing a class or function, we want our code to do something that is not currently possible.
Perhaps the functionality is being worked on by a colleague and they're not done yet, or it's just something we know we'll need in the future, but don't want to work on just yet.
In those scenarios, it's common to leave a comment in our code, noting where this integration will happen:
// TODO: send event data to the analytics
// service once it is ready
void TrackEvent(Event& Event) {}By convention, we prepend TODO or NYI (not yet implemented) to these comments. This means that, before we release, we can do a project-wide text search for TODO to determine if anything is outstanding.
Some tools interact with comments in this style too - for example, the Visual Studio Task List (available from the View menu) presents all of the TODO comments in our project.
Another good place to add comments is to code that is simply too complex to understand. Our first instinct should be to determine if we can reduce the complexity - we provide some examples of that later in the lesson.
But in some scenarios, reducing the complexity is not desirable as it would reduce performance, in a function where performance is very important.
In these contexts, an explanatory comment, often with a link to provide more information, can be very helpful:
// This is an implementation of the Fast
// Inverse Square Root algorithm - see:
// wikipedia.org/wiki/Fast_inverse_square_root
float InvSqrt(float x) {
using std::bit_cast, std::uint32_t;
const float y { bit_cast<float>(
0x5f3759df - (bit_cast<uint32_t>(x) >> 1)
)};
return y * (1.5f - (x * 0.5f * y * y));
}Commenting to Give Context
Often, comments are used to explain what complex code is doing, but that is rarely necessary. Anyone who needs to understand what code is doing can take the time to analyze it.
It's often more useful to explain why code is doing something, as that information isn't as easy to regenerate.
Often, we have to do unusual things in our code that may be confusing to anyone reading it in the future. They'll understand what our code is doing, but not why.
When this happens, it can be helpful to add a comment to explain:
void TrackEvent(Event& Event) {
// We redact user email addresses to
// protect personal data and privacy
Event.User.Email = "";
SendToAnalytics(Event);
}Comments as Documentation
When other developers (or ourselves, in the future) want to get an idea of what classes can do, we're generally going to explore in one of two ways:
- Check the header file
- Use IDE features, such as tooltips and autocomplete
We can infer quite a lot in this way. The header files are going to list all the functions and their method signatures.
When we're using an IDE, the UI is typically going to find the public variables and functions of the class we're using and provide some information. By looking at the function name, we can hopefully get an idea of what the function does. Similarly, by looking at the parameter types and names, we can usually get an idea of what arguments we need to provide.
The following screenshot is an example of this from Visual Studio, which calls this feature IntelliSense.
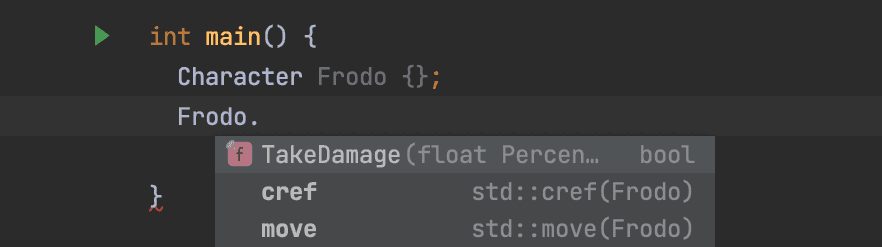
This is useful, but sometimes won't have all the information we might need. Let's look at this function, for example:
bool TakeDamage(float Percent);What is the bool that this function returns? And what is the Percent parameter? Is it the percentage of the character's maximum health? Or current health? Or something else?
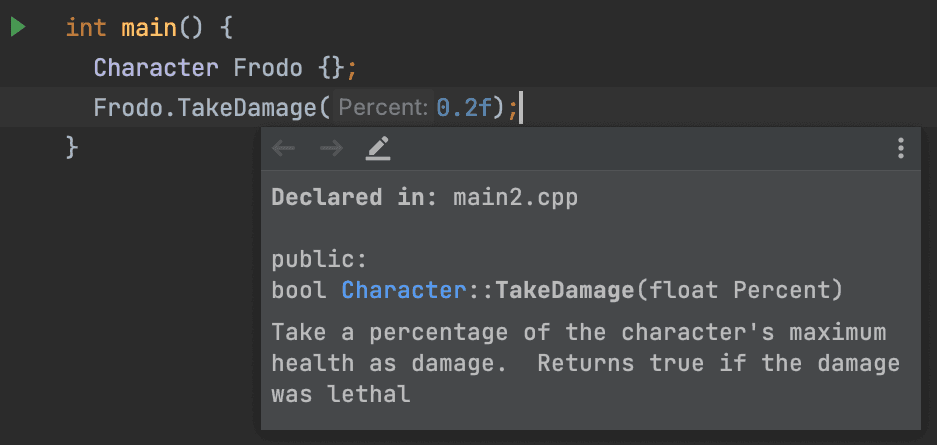
We can further improve IntelliSense and our documentation by adding comments to our header file. By adding a simple comment above the method signature, our code can be described in plain language:
/* Take a percentage of the character's
* maximum health as damage. Returns
* true if the damage was Lethal
*/
bool TakeDamage(float Percent){};Most IDEs will also show this comment when we use our classes, or hover over calls to our function:
Structured Comments and Javadoc
Comments can be even more powerful when we follow a specific pattern. If we format our comments in a structured style, other systems will be able to read and understand our comments at a programmatic level.
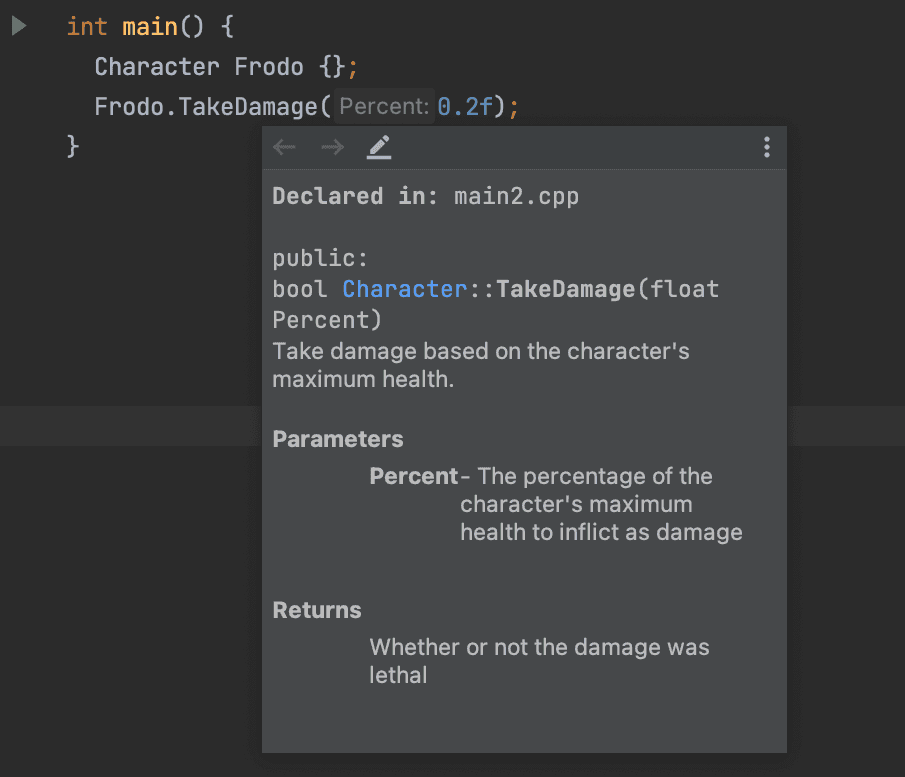
Take this style of commenting, for example:
/**
* Take damage based on the character's
maximum health.
* @param Percent - The percentage of the
* character's max health to inflict as damage
* @return Whether or not the damage was lethal
*/
bool TakeDamage(float Percent);If we now view our tooltip in our editor, it is likely to have been formatted in a more structured way.
These are called Javadoc-style comments, which were popularised by a documentation generator created for the Java programming language. It features many more properties than those demonstrated here. Javadoc comments can include things like:
- links to websites
- references to other blocks of code
- flags to inform users that the function is deprecated and they should probably use something else
When we create comments in a specific manner, they can be read and understood not just by humans, but also by other tools. As we've seen, this includes our IDE, but there are many more use cases.
For example, Doxygen can use comments written in this style to automatically create documentation websites for our projects.
The Problem with Comments
Whilst comments are often useful, they can often be misused as a way to mitigate messy code.
Ideally, our code should require as few comments as possible. We should strive to make our code as simple as possible, rather than having complex code and explanatory comments.
If code is confusing, our first instinct should be to determine if we can make it less confusing, rather than explain it with comments.
Code that strives to be as understandable to humans as possible, without needing additional comments or documentation, is sometimes referred to as self-documenting code.
Making our code clearer has several advantages over using comments to explain complex code. The two main advantages are:
- Code is the real "source of truth". Comments are ignored by the compiler, so can be misleading/wrong. This often happens as a result of future code changes, that neglect to also update the associated comments
- The process of refactoring code to be "self-documenting" almost always improves it, making future work easier.
The rest of this section outlines the four most common ways to replace comments with better code.
Removing Unnecessary Comments
Another common misuse of comments is those that simply explain what the code is doing. These are unnecessary and simply add noise and maintenance overhead:
int Add(int x, int y) {
// Return the result of adding x and y
return x + y;
}Renaming or Adding Variables
Often, a comment that describes what a variable does can be replaced by simply improving the variable name. We can improve the following code:
// The aggression level
int Level { 0 };We just need to use a more descriptive variable name:
int AggressionLevel { 0 };Additionally, we often have literals in our code that warrant an explanatory comment. These literals are sometimes called "magic strings" or "magic numbers" - seemingly arbitrary values that have some special, non-obvious, meaning.
// Unicode character for a smiling emoji
Chat.Send("U+1F600");
// This URL returns our special offers
HTTP::Get("https://192.63.27.92");We can make that relationship concrete and self-documenting by just creating variables.
string SmilingEmoji { "U+1F600" };
Chat.Send(SmilingEmoji);
string SpecialOffers { "https://192.63.27.92" };
HTTP::Get(SpecialOffers);Introducing Descriptive Types or Aliases
Another common source of comments is documenting properties associated with types. We might have a variable or a set of variables that have some semantic meaning that is not immediately clear. Below, we have three floats, and their relationship is established just through a comment
// x, y, and z positions in the world
float x { 0 };
float y { 0 };
float z { 0 };Instead, we can introduce a new type that makes that relationship concrete:
struct Position { float x; float y; float z; }
Position WorldPosition { 0, 0, 0 };Enum types are often useful for this purpose, too. Below, we have an int type where the values have some hidden meaning, which we've documented in a comment:
// 0 is friendly, 1 is neutral, 2 is hostile
int AggressionLevel { 0 };Instead, we should add an enum type to handle this:
enum class Aggression {
Friendly, Neutral, Hostile };
auto AggressionLevel{Aggression::Friendly};Where an existing type does not exactly match our requirements but comes close, we may be tempted to use it with some comments:
// Returns ability damage as a std::pair
// first is damage, second is crit chance
std::pair<int, float> GetDamageValues();Instead, we should consider just introducing a new, self-documenting type:
struct AbilityDamage {
int Damage; float CritChance;
};
AbilityDamage GetDamageValues();Even if a more generic type does match our requirements, we sometimes feel a comment is warranted to specifically explain what that type contains:
// This vector only contains the abilities
// that have already been learned
std::vector<Ability> SpellBook;Instead, we can do this with a type alias:
using LearnedAbilities = std::vector<Ability>;
LearnedAbilities SpellBook;Decomposing Problems using Helper Functions
When we create a complex function, composed of multiple parts, our first instinct is often to describe what is going on in that function by introducing a lot of comments.
Let's imagine we have a complex member function that looks something like this:
class Character {
public:
bool Attack(Character* Target) {
// Make sure we have a target, and it is
// valid to attack it
if (!Target) return false;
if (Target.Hostility == Friendly) {
return false;
}
// Target is attackable, but we need to make
// sure it is in range
float[x1, y1, z1] = MyPosition;
float[x2, y2, z2] = Target->Position;
float x = x1 - x2;
float y = y1 - y2;
float z = z1 - z2;
// The square root of these values will be
// the distance
float Distance{(x * x) + (y * y) + (z * z)};
if (sqrt(Distance) <= 10) {
// Attack was successful
Target->TakeDamage();
return true;
}
// Attack was unsuccessful
return false;
}
};Breaking a big problem into smaller functions makes our code simpler, and allows us to replace our comments with descriptive function names instead.
A function that does part of the computation of another function is sometimes referred to as a helper function.
As an additional benefit, quite often these smaller, more generic functions can be useful in multiple places. This can make future work easier, by reducing the amount of code we have to write and maintain.
For the above function, we can simplify it by introducing two helper functions - isValidTarget() and GetDistance():
class Character {
public:
bool Attack(Character* Target) {
if (!isValidTarget(Target)) return false;
Target->TakeDamage();
return true;
}
// ... other public members
private:
bool isValidTarget(const Character* Target) {
if (!Target) return false;
if (Target.Hostility == Friendly) {
return false;
}
return GetDistance(Target->Position) > 10)
}
float GetDistance(Position TargetPosition) {
float[x1, y1, z1] = MyPosition;
float[x2, y2, z2] = TargetPosition;
float x = x1 - x2;
float y = y1 - y2;
float z = z1 - z2;
return sqrt((x * x) + (y * y) + (z * z));
}
// ... other private members
};Summary
This lesson provides an introduction to effective commenting and documentation. We covered:
- Types of Comments: Reviewing single-line (
//) and multi-line (/* */) comments. - Purposeful Commenting: Learning when and how to comment, including using comments for future work (
TODO,NYI) and explaining complex code. - Contextual Comments: Emphasizing the importance of comments that give context and explain the 'why' behind code decisions.
- Javadoc and Documentation: Introducing structured commenting styles like Javadoc for better documentation and tool integration.
- Self-documenting Code: Strategies for writing code that is self-explanatory, reducing the reliance on external comments.
Style Guides and Automatic Code Formatting
This lesson introduces the concept of Style Guides and ClangFormat, focusing on how to achieve consistency in our code
Comments to Explain Complexity